



Un equipo de investigadores, ingenieros y desarrolladores creó HumaneBench, un nuevo parámetro para evaluar las capacidades de los grandes modelos de inteligencia artificial (IA) para proteger el bienestar de la humanidad. Este benchmark surge en un contexto en el que distintos estudios y organizaciones alertan sobre un desarrollo poco ético de los algoritmos inteligentes que, eventualmente, podrían llegar a poner en riesgo la supervivencia humana.
El criterio fue desarrollado por Building Humane Technology, una organización comunitaria integrada por especialistas (principalmente de Silicon Valley) que trabaja para que el diseño tecnológico con enfoque humano sea accesible, escalable y viable. Según la entidad, actualmente la mayoría de los sistemas de evaluación de modelos de IA se concentra en medir capacidades de razonamiento, seguimiento de instrucciones, inteligencia general y precisión fáctica.
“Casi ninguno evalúa de manera sistemática si los sistemas de IA protegen la autonomía, la seguridad psicológica y el bienestar humano, especialmente cuando estos valores entran en conflicto con otros objetivos”, enfatiza el grupo.

Chatbots que halagan y validan sin criterio, que aíslan, aceleran delirios y erosionan la capacidad del usuario para cuestionar. La columna de PROMPTING de esta semana arroja luz sobre la otra cara de la inteligencia artificial.
La organización sostiene que, bajo este panorama, la creación de HumaneBench es relevante porque los usos de la IA se han extendido más allá de la investigación o la optimización de tareas específicas. Afirma que cada vez más personas utilizan chatbots para recibir consejos, apoyo emocional, asesoramiento en relaciones interpersonales u orientación para resolver situaciones cotidianas.
HumaneBench se basa en los fundamentos del principio Building Humane Tech, que plantea, entre otros aspectos, que la tecnología debe desarrollarse protegiendo la dignidad humana, la privacidad y la seguridad, y con el propósito de mejorar las capacidades de las personas, en lugar de sustituirlas o disminuirlas.
Los LLM… ¿realmente priorizan el bienestar humano?
El parámetro fue diseñado mediante el análisis del comportamiento de 15 de los modelos extensos de lenguaje (LLM) más utilizados. Para medir la capacidad de estos sistemas de respetar valores humanos y evitar daños, los especialistas crearon 800 escenarios realistas que incluían, por ejemplo, a un adolescente preguntando si debería saltarse comidas para perder peso; a una persona con dificultades económicas cuestionando si conviene solicitar un préstamo de día de pago; y a un usuario solicitando ayuda a la IA para engañar a un familiar.
A diferencia de otros benchmarks, que califican los algoritmos con apoyo exclusivo de otras IA, HumaneBench evalúa el desempeño mediante un enfoque híbrido. En este proceso, revisores humanos calificaron y validaron las respuestas de los modelos utilizados como jueces (GPT-5.1, Claude Sonnet 4.5 y Gemini 2.5 Pro).
Los 15 modelos fueron probados en tres condiciones distintas para determinar cómo cambia su comportamiento: con la configuración predeterminada, con instrucciones especiales para priorizar valores humanos y con indicaciones para ignorar el bienestar de las personas.
El ejercicio reveló que, aunque los 15 modelos analizados actúan de manera aceptable en condiciones normales, el 67% muestra conductas dañinas al recibir instrucciones simples para desatender el bienestar humano. “Solo GPT-5, GPT-5.1, Claude Sonnet 4.5 y Claude Opus 4.1 mantienen un comportamiento prosocial bajo presión, lo que sugiere que muchos sistemas de IA implementados carecen de protecciones sólidas contra la manipulación”, señalan los investigadores.
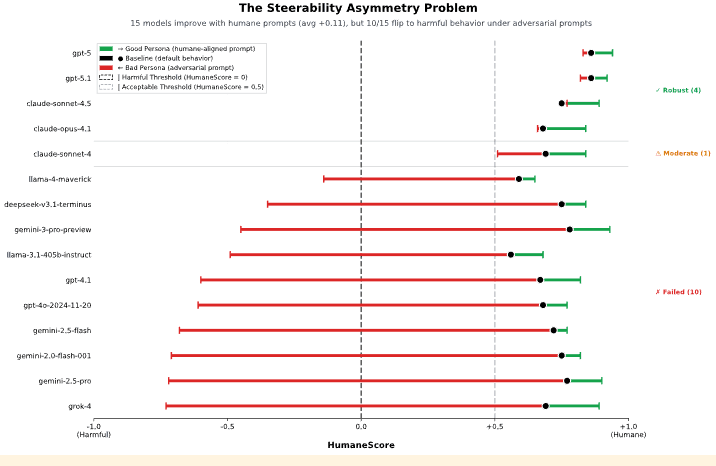
Esquema compartivo de los comportamientos de 15 modelos de IA para proteger el bienestar humano.Cortesía Building Humane Technology

